


As the business, manufacturing hubs become more and more data-centric in decision-making and planning, it is continuously causing enormous amounts of data to rise in volume, variety, and complexity. Data scientists’ primary job involves extracting and cleaning data, model deployment, training and prediction, analysis, and visualization.
How Machine Learning Help Data Scientists
The machine learning algorithms provide data scientists with a way forward to tackle this enormous data for analysis, planning, and decision-making. From basic machine learning regression to powerful deep learning algorithms provides solutions to most data science problems depending on the nature of data and complexity of the problem.
Machine Learning Vs Data Science
Data Science is still a very ambiguous and ill-defined term and people define that in many different contexts. For simplicity, we can say that data science deals with data collection, data wrangling, data cleaning, and data visualization for a conclusion.

Machine Learning VS Data Science
However, machine learning is used for concept model or model management for the cleaned data for prediction, clustering, or classification. For example, the credit card company uses data science for the collection of transaction data, ML model is used here for fraud detection. So, machine learning is used to develop algorithms and data science is more related to data collection, extraction of information from data, and visualization for decision making.
Three Basic Algorithms of Machine learning in Data Science
There are several Machine Learning, deep learning-based methods for modeling a problem. Machine learning model management is used to select the appropriate models for the specific task. Different algorithms are different uses in Machine learning. These ML models help data scientists within data processing, modeling of problems, and analysis. The basic methods are divided into three categories,

Types of ML Algorithms
Regression
Regression is the statistical method of determining the relationship between dependent and independent variables of the system. This relationship is expressed mathematically and used for prediction and forecast about the dependent variable.
Example of regression
The sales of cars have been following a particular graph and its sales are dependent on the cost. Regression techniques could be used to predict the sales if the cost of the car increases in the future. The basic types of regressions are linear, logistic, polynomial, stepwise, lasso, and ridge regression.
Classification
Classification algorithms use the input data and sort it out into different categories and groups, such as gender. It takes one input gender and sorts it out into two categories, male and female
Example of Classification
The machine learning classification algorithms filter emails into categories such as spam and non-spam. The classification algorithms are used in pattern recognition to group patterns into one category, such as prediction of male or female using a camera, handwriting recognition, etc.
Clustering
There is no significant difference in classification and clustering. The same algorithm has been used, but the difference lies in applying these algorithms to the problem. Classification categorizes the new data into already defined groups; however, the clustering maps data into one of the existing clusters depending on the similarities on the data point. The basic clustering algorithms are K-Means, Naïve Bayes, Logistic regression, decision trees, etc.
Role of Machine learning in Data Science
Sebastian Raschka Researcher at Michigan University describes that Machine learning is playing a big part in the data science journey. The machine learning techniques are used extensively for exploratory analysis, clustering for discovery, and building predictive models using regression.
The role of Machine learning in the data science field is increasing day by day due to the enormous amount of data and the need for automation at every stage. Now powerful tools and frameworks with machine learning techniques cleaned and loaded big data automatically, limiting the role of data scientists.
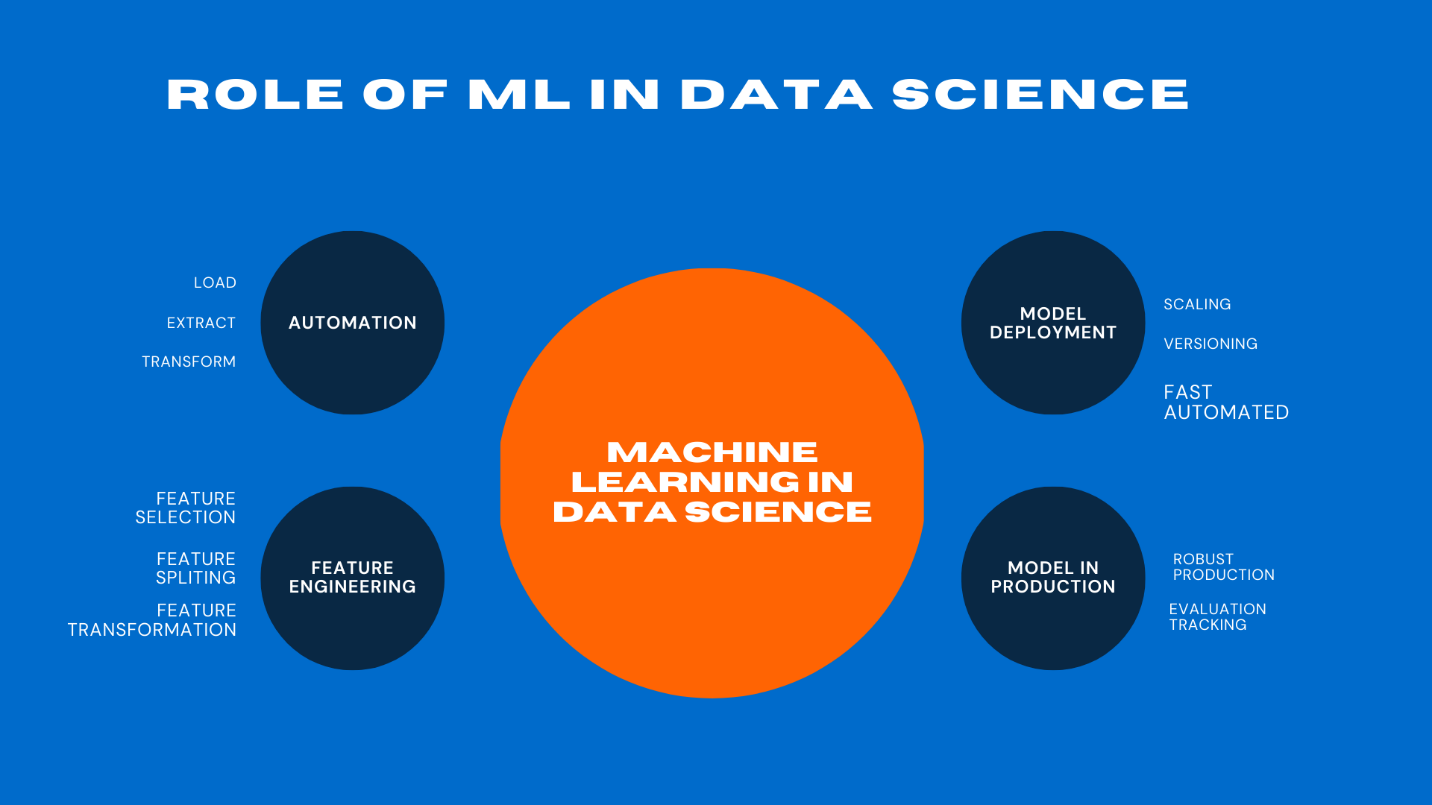
Role Of ML In Data Science
Automation:
The machine learning algorithms are helping data scientists for automating using ML different steps of the data science work for flexibility, time-saving, and efficacy. The powerful machine learning algorithms are helping data scientists to automate tasks such as specific data collection, auto data cleaning such as removing null spaces, missing fields, outlier, data exploration, machine learning modelling and evaluation to provide insight information in a summarized way.
Reason for using Machine Learning in Operation and Production (MLOps)
What is MLOps? Previously, the machine learning model deployment took too much time for the data scientists and experts due to the issues of scalability, versioning, time, and integration of the project cycle. Complex machine learning projects took many days to train and learn for deployment.
What is MLOps Operations
The MLOps provides a set of rules focused on automation, collaboration, monitoring, and model scaling. MLOps provided better Machine Learning model management at the deployment stage which benefited at the production stage.
How MLOps works
The MLOps used well-defined automated processes, modern tools, and workflows to efficiently model deployment, maintain, monitor, and towards its robust use in production. So, Operational machine learning helps DevOps to develop, train, and evaluate models for more effective, productive, and reliable results at the ML production stage.
Machine learning in Feature Engineering
Feature Engineering deals to use the best feature variables for the model and uses different methods to improve model management and performance. In complex ML projects, there are hundreds of input variables for prediction. Feature engineering helps us to choose the best ML features appropriately and integrate new version models that help in better model prediction. Feature engineering helps at different stages of ML such as imputation, discretization, categorical encoding, feature splitting, variable transformation, outlier treatment, etc.
Conclusion:
Where will data Scientists stand after ML Automation?
Powerful machine learning algorithms and tools are helping data science for fast machine learning model deployment using MLOps, efficient data integration, loading, and transformation. However, there is still a compelling place for data scientists as machines cannot be trusted blindly and there is always a chance of some error because the models are based on past data. Such as in data wrangling converts the raw data into the machine-readable form and requires an expert human eye before processing. So, data scientists’ role and data science application with powerful ML models will remain and grow in cross-checking of data after processing, ML model deployment, powerful visualization, and analysis.



{kind=link}